An experience on the open-source Git-CDN project
A wonderfull professional experience at Renault Software Labs
I did my internship at Renault Software Labs at the end of the first year of my master's degree in computer science, from June to September, 2021.
I worked on git-cdn.
1. Context #
1.1 Open-source environment #
Git-cdn has been created by Renault Sotware Labs as an open-source project. It also exists in an internal Gitlab with additional tests and logs. The open-source version remains the reference and the developments are implemented on it, before being merged internally.
As an open-source project, git-cdn takes advantage of the open-source community. Some discussions are done with other external developers who want to benefit from it. This allows improvements coming from other professionals with different knowledges and skills.
1.2 The Git protocol #
https://git-scm.com/book/en/v2/Git-on-the-Server-The-Protocols
Git can use several network protocols to communicate with a central server:
- GIT: the first born, uses raw tcp transport and do not have authentication
- SSH and HTTP(S): variations that use ssh and http(s) protocols for transport and have slight variation of protocol to adapt to the transport specificities. Those variants are fully encrypted and authenticated.
In addition to the transport, Git has stream protocol for encoding messages, command, capabilities and data. This is this level, also named Git protocol, that will be discusted in this blog.
The version 2 of this protocol greatly simplifies the grammar of the stream protocol with new keywords, making it easier to encapsulate, and more adapted to a request/response based protocol that is http(s).
1.3 Git-CDN #
https://gitlab.com/grouperenault/git_cdn
Git-cdn is a Git on demand mirroring solution. Its goals are saving bandwidth of the target site and improving user's practice. It is formed by a central server, and several mirrors, placed wherever it is needed. See the architecture below:

The aim of git-cdn is to duplicate information from the central server into the mirrors. Then, we configure clients to use the mirrors instead of the central server via the insteadOf config. Mirror tries to reply with its local data. If it can not, it will fetch missing data from the central server. It will update its cache and will be able to reply to the client. You can note that the central server is communicating with mirrors only, no client. This is saving a lot of network bandwidth. Mirrors can be placed as needed near the users improving overall experience.
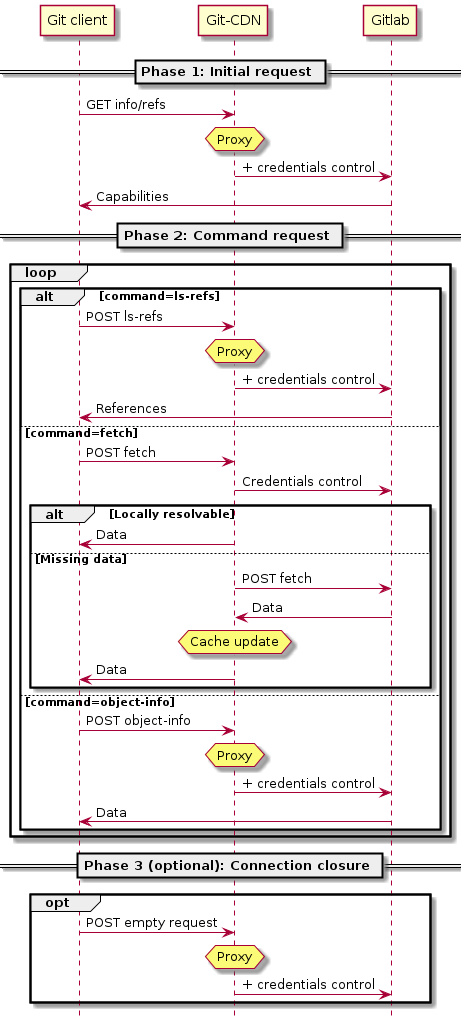
Like I said in the first part, the Git protocol makes its own grammar for the requests. I worked on the second version of that grammar. Here a description of the requests following this version. There are 2 main steps:
- The client asks to communicate and the server replies with the capabilities that it supports
- The client makes one or more command request.
Currently, there are 3 commands available: ls-refs, fetch, and object-info. The ls-refs command allows to know if a repository is up to date. The fetch command is used to get some data/ Git objects. And the object-info command gives some information about a given Git object. A third step exists but it is optional. It indicates the server that the client has finished, and the connection can be closed.
Below, a recap diagram of the communcations of git-cdn following version 2:
1.4 Deployments of Git-CDN #
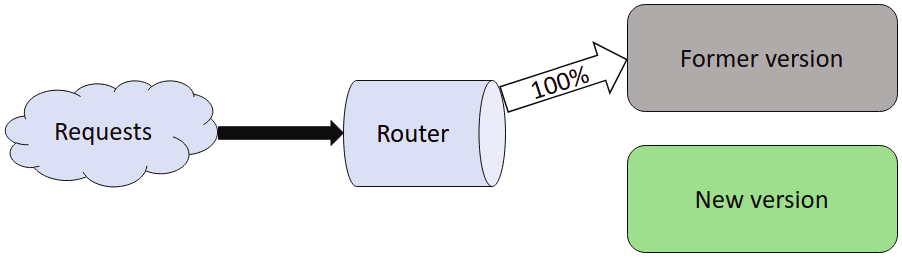
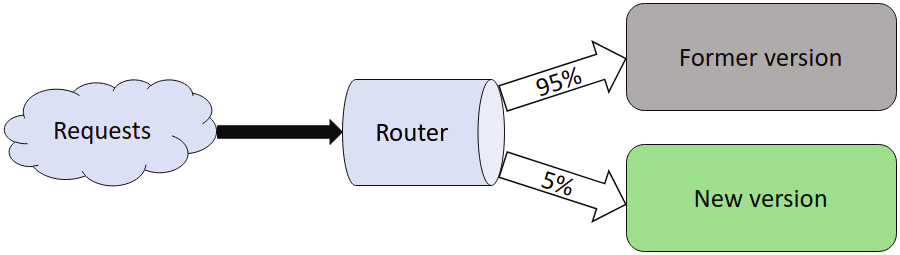
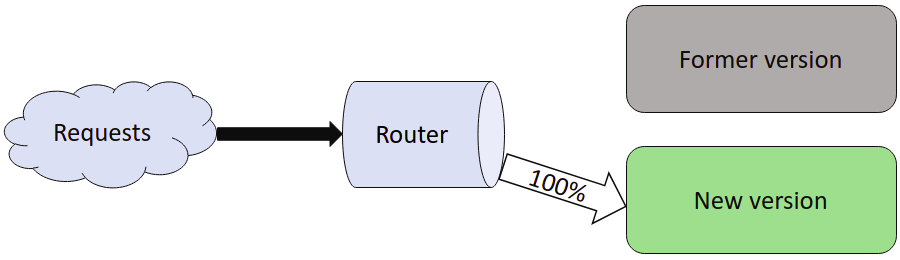
Git-cdn uses a nginx that performs load balancing. Load balancing allows several instance of a service to answer request for a server. It controls the trafic and balance it between those instances. Additionally, when a new version of git-cdn is available, it is deployed on an instance that "takes" 5% of the requests and another instance will take the other requests with the former version. Thus developers can test new version without fully impacting the users in case of bug. We can then do some real life test before confidently deploying the new version at 100% on the server.
Ascending the percentage of the new version is called the canary release. The new version is deployed on a instance with a few trafic, then, if no error appears, the trafic increases up to 100%. It cantake several days before reaching 100%.
Below, a recap of the 3 differents steps of a canary release:
- Before deployment
- Deployment
- Post deployment
2. Implementation of the second version of the Git protocol within Git-CDN #
https://git-scm.com/docs/protocol-v2
The first step was to find the place in the code that would allow me to know if the version 2 of the Git protocol was accepted by the central server, gitlab. This information is sent in the capabilities list by the central server when it agrees to communicate with the client. If the server sends the information that it supports version 2, then the client can choose whether or not to communicate in version 2. Otherwise, version 1 is applied by default. Once this information was known, it was possible for me to direct the execution of git-cdn according to the version used. This step offered me a first approach in the source code, and gave me the opportunity to analyze in more detail the sequence of functions. Also, it allowed me to familiarize myself with the contexts and the logs, which were essential to me in the rest of the internship. One of the big changes between versions 1 and 2, was in the grammar of the requests. I then tackled the writing of the new grammar by following the official documentation. Once finished, this grammar has been the subject of my first deployment. Not yet connected to the rest of the code, because placed in a dedicated class, there was no risk of a new error. Doing such a deployment allowed me to analyze the protocol to follow, without worrying about possible errors. However, this code was still necessary for version 2, and therefore it has been monitored at the next deployment to ensure its proper functioning.
This 2nd deployment took place following the complete implementation of the version 2. Indeed, after writing the grammar, I still had to switch and write some features within the existing source code. In reality this 2nd part began during the writing of the grammar, in order to have a better overview of the final architecture. Also, the two-part deployment (grammar and features) allowed me to familiarize myself with some Git commands. Especially those of plumbing, such as git rebase, which allows to review the history of a directory, and which was very useful to me afterwards. The implementation of this 2nd deployment has been done by following the process I had learned the 1st time. I asked the team responsible for a 5% deployment at Sophia-Antipolis. I then analyzed the logs before requesting a rollback to the old version, because errors were present. Indeed, some windows clients did not respect the grammar as described in the Git documentation, and then returned an error when analyzing the request.
Below, the two versions of the grammar of the requests following the version 2:
- Following the documentation
request = empty-request | command-request
empty-request = flush-packet
command-request = command
capabilities-list
[command-args]
flush-packet
capabilities-list = *capability
command-args = delimiter-packet
*specific-command-args- Done by some Windows clients
request = empty-request | command-request
empty-request = flush-packet
command-request = capabilities-list
[command-args]
flush-packet
capabilities-list = *capability | command
command-args = delimiter-packet
*specific-command-argsThe difference between these two grammars comes from the placement of the command. According to the official documentation, the order must be at the beginning of the request, which some Windows clients do not respect. So when git-cdn analyzed the query, it expected to find the order first, but it found something else with those clients. An error was then returned. However, it is notable that the grammar of those clients on Windows encompasses the official grammar. It was then decided to implement and follow this grammar for everyone, without worrying about the position of the command. After correction, a new deployment was made but infortunatly also required a rollback. This time the error was on the network side, related to the canary deployment strategy. Some clients began to communicate with an instance of git-cdn with the new source code, advertising support for protocol v2 and then, after sending the following requests in v2 protocol, was balanced to an instance still with the old source code, and which therefore did not understand version 2 of the protocol. Below is an illustration of the scenario (arrows in blue) that was problematic:
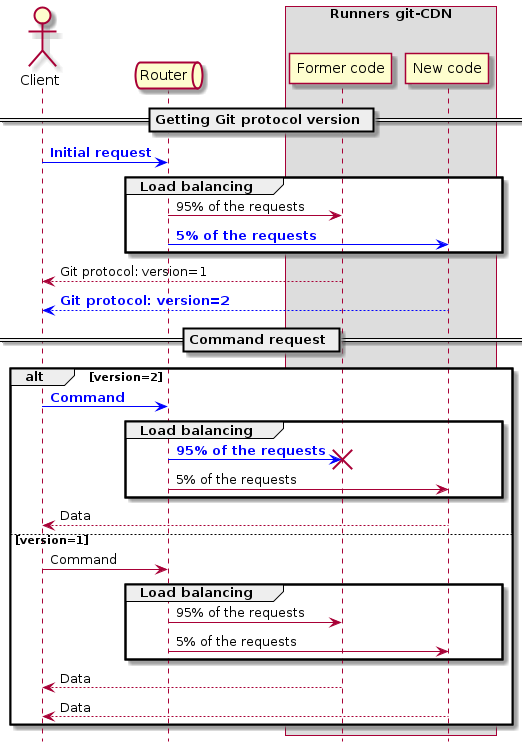
This phenomenon was possible because of the load balancing set up on the git-cdn servers. The solution has been to deploy the new code at 100%. This ensured that whenever a client chose to communicate with version 2, he would always be in communication with a runner that also supported that version. However, the deployment has been done in several phases by deploying site by site, in order to mitigate the risk of this new version. We deployed the new version during several days on the test server before deploying it at Paris, then at Sophia-Antipolis, and finally on the server of Toulouse, the server with the largest activity.
This deployment having seen several twists and turns took a long time. During all of that, I had time to work on another error present since the beginning of git-cdn. This was an error that occurred when references were missing. And so the git upload-pack command, used to retrieve data from the git-cdn cache, could not run completely. To counter this error, the previous version analyzed the response of git upload-pack. If an error was there, then a fetch was made to retrieve the missing references, before relaunching the git upload-pack command. In the new version the trick was to use the git cat-file command upstream of git upload-pack.
Below are the two versions of the code:
- Former version
git("upload-pack")
if error:
fetch()
git("upload-pack")- New version
git("cat-file")
if missing refs:
fetch()
git("upload-pack")Indeed the git cat-file command allows you to know if a reference exists or not in a Git directory. Thus, if a reference is missing, then a fetch is made and the git upload-pack command can run. Despite the tests carried out, it was still agreed with the rest of the team that this new strategy would initially keep the verification of the error. It was only after deployment, and verifying that the new policy was working correctly, in a production environment, that the old policy has been deleted.
3. Other features #
The rest focused on activities defined during the internship following discussions and discoveries. Notably, there has been a new version of the documentation for the version 2 of the Git protocol. This version introduced a new command, object-info, in addition to the two already existing ls-refs and fetch. The grammar was therefore revised to support this command, and I took the opportunity to review the management of unknown commands. Indeed, when the grammar was first written, the unknown commands returned an error, but this did not mean that the command did not exist, and that gitlab was not able to understand it. This error was replaced by a warning, in order to warn of a potential new command, and git-cdn became a simple proxy, leaving gitlab to handle the command and the possible error. Before making the 3rd deployment, a final development has been made. It was about the management of updates to the git-cdn cache in case of competition between processes. Indeed, when the cache needs to be updated, a write lock must be taken. However, several processes may want to update the cache. To prevent the cache from being updated by all processes, git-cdn uses the mtime of a directory. This mtime is the date the associated directory was last updated. So a process, before requesting the write lock, will look at this mtime, of the directory it wants to update. It then asks for the lock and then look for the mtime again. If the latter is identical to the one requested at the beginning, then the directory has not been updated. The process knows that it is the first to manage to get the write lock can then update it. Otherwise, where the mtime would be different, this means that the directory has been updated in the meantime, and it is then not necessary to update it on more time.
Below is the new code version:
prev_mtime = cache.mtime()
with take_write_lock():
if prev_mtime == cache.mtime():
fetch()
# implicit write lock freeHowever, this architecture is the result of a rewriting of the source code. Indeed the previous version was not very clear. It had been discussed to change this strategy by the git cat-file command, which had been integrated a few days earlier, but its development was inconclusive, and a simple, clearer rewrite of the source code was carried out.
Finally I started a new feature of Git: packfile-uris. The latter aimed to implement a new cache strategy, in order to compare it with the current one, and to see the potential gains. This is because packfile-uris allows a server to return part of its response in the form of a URI, which allows it to return less data, and therefore to gain bandwidth and CPU. However this feature was very recent (February 2021) and the documentation was not abundant. I then resorted to local tests and analyses, in order to understand how it works. As I progressed in my research, I looked to implement and test it as soon as possible.
4. Conclusion #
To conclude, the objective of my internship has been achieved. Namely: implement the version 2 of the Git protocol within git-cdn. This goal has been achieved through several steps during which I discovered and faced various situations. During the internship, these phases have been completed and followed by new activities arriving following discussions, discoveries or flourishing ideas. Some intended to improve the efficiency of git-cdn, others to add a non-existent capability, or to review and to improve existing code. I could see other facets of git-cdn and not only the part dedicated to the version 2 of the protocol.
- Previous: Introducing Gitlab Project Configurator.